



这两天,Apple Intelligence 的上线成为了最大的科技新闻之一。
虽然相比 1 个多月前公布的完整版 Apple Intelligence,苹果 iOS 18.1 beta 1 中引入的 Apple Intelligence 功能并不完整,Image Playground、Genmoji、优先通知、具有屏幕感知功能的 Siri 和 ChatGPT 集成……这些统统都还没有。
但总的来说,苹果还是带来了 Writing Tools(写作工具)、通话录音(含转录)以及全新设计的 Siri。
其中,Writing Tools 支持重写、专业化、简略等功能,可以用于聊天、发朋友圈、小红书笔记以及文本写作等场景;通话录音不仅可以记录通话,还能自动转录成文本,方便用户回顾。
此外,Siri 也得到了「升级」,可惜目前还仅限于设计,包括全新的「跑马灯」特效以及键盘输入支持。
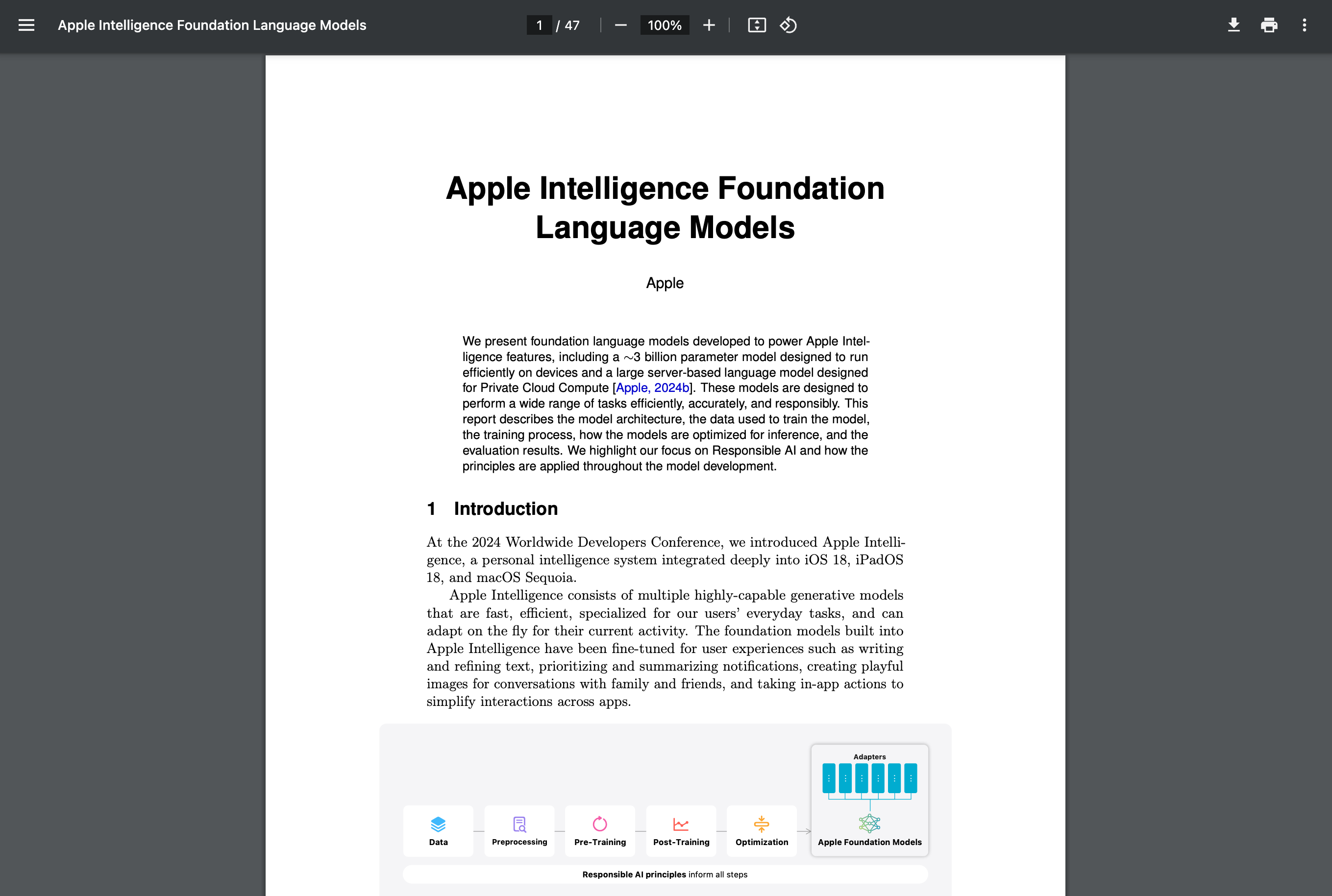
但引人注目的是,苹果在一篇名为《Apple Intelligence Foundation Language Models》的论文中披露,苹果并没有采用常见的英伟达 H100 等 GPU,而是选了「老对手」谷歌的 TPU,训练 Apple Intelligence 的基础模型。
图/苹果
用谷歌 TPU,炼成 Apple Intelligence
众所周知,Apple Intelligence 总共分成三层:一层是运行在苹果设备本地的端侧 AI,一层是基于「私有云计算」技术运行在苹果自有数据中心的云端 AI。按照供应链传出的消息,苹果将通过大量制造 M2 Ultra 来构建自有数据中心。
此外还有一层,则是接入第三方云端大模型,比如 GPT-4o 等。
不过这是推理端,苹果是如何训练出自己的 AI 模型,一直是行业内关注的焦点之一。而从苹果官方的论文来看,苹果是在 TPUv4 和 TPUv5p 集群的硬件上训练了两个基础模型:
一个是参数规模达到 3 亿的设备端模型 AFM-on-device,使用 2048 块 TPU v5p 训练而成,本地运行在苹果设备上;一个是参数规模更大的服务器端模型 AFM-server,使用 8192 块 TPU v4 芯片训练,最终运行在苹果自有数据中心里。

图/苹果
这就奇怪了,毕竟我们都知道,英伟达 H100 等 GPU 才是目前训练 AI 的主流选择,甚至会有「AI 训练只用 Nvidia GPU」的说法。
与之相对,谷歌的 TPU 就显得有些「名不见经传」。
但事实上,谷歌的 TPU 是专为机器学习和深度学习任务设计的加速器,能够提供卓越的性能优势。凭借其高效的计算能力和低延迟的网络连接,谷歌的 TPU 在处理大型模型训练任务时表现出色。
例如,TPU v4 就能提供了每个芯片高达 275 TFLOPS 的峰值算力,并通过超高速互连将 4096 个 TPUv4 芯片连接成一个大规模的 TPU 超算,从而实现算力规模的倍增。
而且不仅是苹果,其他大模型公司也采用了谷歌的 TPU 来训练他们的大型模型。Anthropic 公司的 Claude 就是一个典型的例子。
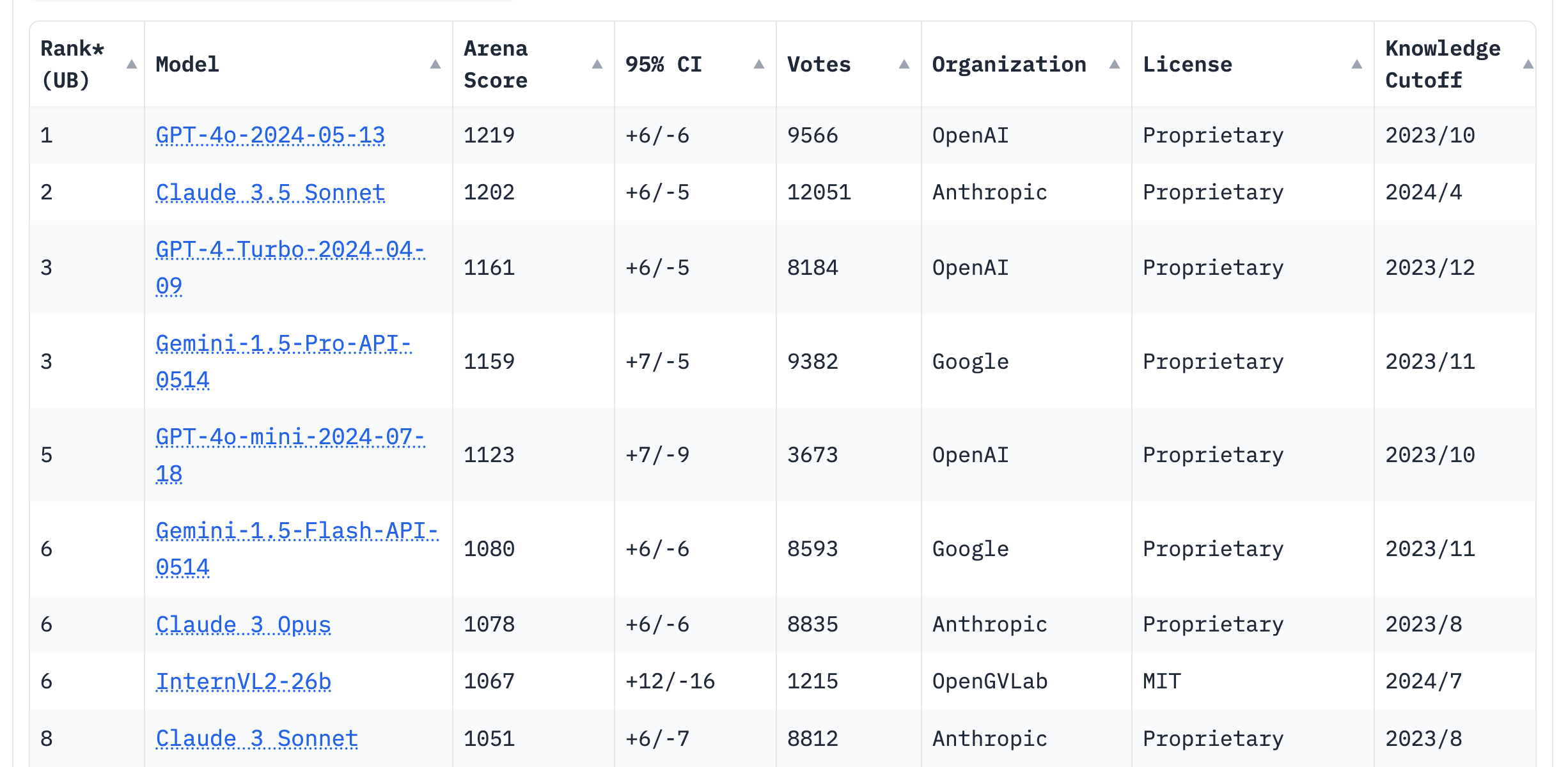
聊天机器人竞技场排行,图/LMSYS
Claude 如今可以说是 OpenAI GPT 模型最强大的竞争对手,在 LMSYS 聊天机器人竞技场上,Claude 3.5 Sonnet 与 GPT-4o 始终是「卧龙凤雏」(褒义)。而据披露,Anthropic 一直没有购买英伟达 GPU 来搭建超算,就是使用 Google Cloud 上 TPU 集群来训练和推理。
去年底,Anthropic 还官宣率先使用 Google Cloud 上的 TPU v5e 集群来训练 Claude。
Anthropic 的长期使用,以及 Claude 表现出来的效果,都充分展示了谷歌 TPU 在 AI 训练中的高效性和可靠性。
此外,谷歌的 Gemini 也是完全依赖于自研的 TPU 芯片进行训练。Gemini 模型旨在推进自然语言处理和生成技术的前沿,其训练过程需要处理大量的文本数据,并进行复杂的模型计算。
而 TPU 的强大计算能力和高效的分布式训练架构,使得 Gemini 能够在相对较短的时间内完成训练,并在性能上取得显著突破 。
但如果说 Gemini 尚可理解,那从 Anthropic 到苹果又为什么选择谷歌 TPU,而不是英伟达 GPU?
TPU 和 GPU,谷歌和英伟达的暗战
在本周一举办的计算机图形学顶级会议 SIGGRAPH 2024 上,英伟达创始人兼 CEO 黄仁勋透露,本周英伟达就将发送 Blackwell 架构的样品,这是英伟达最新一代的 GPU 架构。
2024 年 3 月 18 日,英伟达 GTC 大会上发布了其最新一代 GPU 架构——Blackwell,以及最新一代 B200 GPU。在性能上,B200 GPU 在 FP8 及新的 FP6 上可以达到 20 petaflops(每秒千万亿次浮点运算)的算力,使其在处理复杂 AI 模型时表现出色。
Blackwell 发布的两个月后,谷歌也发布了其第六代 TPU(Trillium TPU),每块芯片在 BF16 下可以提供接近 1000 TFLOPS(每秒万亿次)的峰值算力,谷歌也将其评价为「迄今为止性能最高、最节能的 TPU」。

图/谷歌
对比谷歌的 Trillium TPU,英伟达 Blackwell GPU 在高带宽内存(HBM3)和 CUDA 生态系统的支持下,在高性能计算中仍然有着一定的优势。在单个系统中,Blackwell可以并行连接多达 576 个 GPU,实现强大的算力和灵活的扩展性。
相比之下,谷歌的 Trillium TPU 则注重在大规模分布式训练中的高效性和低延迟。TPU 的设计使其能够在大规模模型训练中保持高效,并通过超高速网络互连减少通信延迟,从而提高整体计算效率。
而不仅是在最新一代的 AI 芯片上,谷歌与英伟达之间的「暗战」实际已经存在了 8 年,从 2016 年谷歌自研 AI 芯片 TPU 就开始。
到今天,英伟达的 H100 GPU 是目前主流市场上最受欢迎的 AI 芯片,不仅提供了高达 80GB 的高带宽内存,还支持 HBM3 内存,并通过 NVLink 互连实现多 GPU 的高效通信。基于 Tensor Core 技术,H100 GPU 在深度学习和推理任务中具有极高的计算效率。
但同时,TPUv5e 在性价比上具有显著优势,特别适合中小规模模型的训练。TPUv5e 的优势在于其强大的分布式计算能力和优化的能耗比,使其在处理大规模数据时表现出色。此外,TPUv5e 还通过谷歌云平台提供,便于用户进行灵活的云端训练和部署。

谷歌数据中心,图/谷歌
整体来说,英伟达和谷歌在 AI 芯片上的策略各有侧重:英伟达通过提供强大的算力和广泛的开发者支持,推动 AI 模型的性能极限;而谷歌则通过高效的分布式计算架构,提升大规模 AI 模型训练的效率。这两种不同的路径选择,使得它们在各自的应用领域中都展现出了独特的优势。
不过更重要的是,能打败英伟达的,也只有采用软硬件协同设计策略,同时拥有强大的芯片能力和软件能力的对手。
谷歌就是这样一个对手。
英伟达霸权的最强挑战者
Blackwell 是继 Hopper 之后英伟达的又一重大升级,具有强大的计算能力,专为大规模语言模型(LLM)和生成式 AI 而设计。
据介绍,B200 GPU 采用了台积电 N4P 工艺制造,拥有多达 2080 亿个晶体管,由两块 GPU 芯片采用互连技术「组成」,并且配备了高达 192GB 的 HBM3e(高带宽内存),带宽可达 8TB/s。
而在性能上,谷歌的 Trillium TPU 相比上一代 TPU v5e 在 BF16 下提升了 4.7 倍,HBM 容量和带宽、芯片互连带宽也都翻了一番。此外,Trillium TPU 还配备了第三代 SparseCore,可以加速训练新一代基础模型,延迟更低,成本也更低。
Trillium TPU 特别适合大规模语言模型和推荐系统的训练,可以扩展出数百个 集,通过每秒 PB 级别的网络互连技术连接数以万计的芯片,实现另一种层面的超级「计算机」,大幅提升计算效率和减少网络延迟。

图/谷歌
从今年下半年开始,Google Cloud 用户就能率先采用这款芯片。
总的来说,谷歌 TPU 的硬件优势在于其高效的算力和低延迟的分布式训练架构。这使得 TPU 在大规模语言模型和推荐系统的训练中表现出色。然而,谷歌 TPU 的优势还在于独立于 CUDA 之外另一个完整的生态,以及更深度的垂直整合。
通过 Google Cloud 平台,用户可以灵活地在云端进行训练和部署。这种云端服务模式不仅减少了企业在硬件上的投入,还提高了 AI 模型的训练效率。Google、 Cloud 还提供了一系列支持 AI 开发的工具和服务,如 TensorFlow 和 Jupyter Notebook,使开发者能够更加便捷地进行模型训练和测试。

苹果用上的谷歌 TPU v5p,图/谷歌
谷歌的 AI 生态系统中还包含了多种开发工具和框架,如 TensorFlow,这是一个广泛使用的开源机器学习框架,能够充分利用 TPU 的硬件加速功能。谷歌还提供了其他支持 AI 开发的工具,如 TPU Estimator 和 Keras,这些工具的无缝集成大大简化了开发流程。
此外,谷歌的优势还在于:谷歌自己就是对 TPU 算力需求最大的客户。从 YouTube 海量视频内容的处理,到 Gemini 的每一次训练和推理,TPU 早就融入谷歌的业务体系之中,也满足了谷歌的巨量算力需求。
可以说,谷歌的垂直整合远比英伟达来得彻底,几乎完全掌握了从模型训练到应用,再到用户体验的关键节点,这实际也给了谷歌更大的可能,可以根据技术和市场趋势从底层开始优化效率。
所以尽管在芯片的性能指标上,Trillium TPU 依然难以和 Blackwell GPU 相抗衡,然而具体到大模型的训练上,谷歌仍能通过系统性地优化效率,比肩甚至超越英伟达 CUDA 生态。
在 Google Cloud 用 TPU,是苹果最好的选择
简言之,谷歌 TPU 集群性能、成本和生态的优势,使其成为大规模 AI 模型训练的理想选择。反过来,在 Google Cloud 用 TPU 也是苹果现阶段最好的选择。

基于 TPU v4 的超算,苹果也用到了。图/谷歌
一方面是性能和成本。TPU 在处理大规模分布式训练任务时表现出色,提供高效、低延迟的计算能力,满足苹果在 AI 模型训练中的需求。而通过使用 Google Cloud 平台,苹果可以降低硬件成本,灵活调整计算资源,优化 AI 开发的总体成本。
另一方面是生态。谷歌的 AI 开发生态系统也提供了丰富的工具和支持,使得苹果能够更高效地开发和部署其 AI 模型,再加上 Google Cloud 的强大基础设施和技术支持也为苹果的 AI 项目提供了坚实的保障。
今年 3 月,曾经任职于英伟达、IBM 和谷歌的 Sumit Gupta 加入了苹果,领导云基础设施。根据报道,Sumit Gupta 于 2021 年加入谷歌的 AI 基础设施团队,并最终成为了谷歌 TPU、自研 Arm CPU 等基础设施的产品经理。
Sumit Gupta 比苹果内部绝大部分人都更了解谷歌 TPU的优势所在。
2024上半年,科技圈风起云涌。
大模型加速落地,AI手机、AI PC、AI家电、AI搜索、AI电商……AI应用层出不穷;
Vision Pro开售并登陆中国市场,再掀XR空间计算浪潮;
HarmonyOS NEXT正式发布,移动OS生态生变;
汽车全面进入“下半场”,智能化成头等大事;
电商竞争日益剧烈,卷低价更卷服务;
出海浪潮风起云涌,中国品牌迈上全球化征程;
……
7月流火,雷科技·年中回顾专题上线,总结科技产业2024上半年值得记录的品牌、技术和产品,记录过去、展望未来,敬请关注。





